📌 CNN에서 이미지 데이터 형태는?
이미지 데이터는 보통 다음과 같은 3차원 형태를 가짐:
(높이, 너비, 채널)=(H,W,C)\text{(높이, 너비, 채널)} = (H, W, C)
구성 요소의미예시
| 높이 (Height) | 이미지 세로 크기 | 28, 64, 224 등 |
| 너비 (Width) | 이미지 가로 크기 | 28, 64, 224 등 |
| 채널 (Channel) | 색상 정보 | 흑백: 1, RGB: 3 |
🎯 예시 시작: 28x28 RGB 이미지 입력
입력 이미지 크기: (28, 28, 3) → RGB 이미지 (예: 컬러 손글씨 이미지)
🧱 [1단계] 합성곱 층 (Conv Layer)
💡 역할:
- **필터(kernel)**를 통해 특징 추출 (윤곽선, 패턴 등)
- 필터는 슬라이딩하면서 이미지의 작은 부분만 본다
📌 적용 예시:
- 입력: (28, 28, 3)
- 필터 수: 32개, 필터 크기: 3x3, stride=1, padding='same'
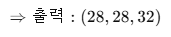
| 채널이 3 → 32로 증가 (특징 맵 32개 생성됨) |
| 공간 크기는 동일 (padding='same'일 경우) |
🧱 [2단계] 풀링 층 (Pooling Layer)
💡 역할:
- 특징 맵의 공간 크기를 줄임(Downsampling)
- 연산량 줄이고, 위치에 덜 민감하게 함
📌 Max Pooling 예시:
- 입력: (28, 28, 32)
- 풀링 크기: 2x2, stride=2

| 채널 수는 그대로 (32) |
| 가로/세로 크기 절반으로 감소 (연산량 감소) |
🧱 [3단계] 다시 Conv + Pooling 반복 (선택)
추가 Conv → (14, 14, 64)
Pooling → (7, 7, 64)
→ 보통 이 과정을 여러 번 반복해서 깊은 특징 추출
🧱 [4단계] Flatten + Fully Connected (FC)
Flatten
- 입력: (7, 7, 64)
- Flatten → (7 × 7 × 64) = (3136,)
CNN 출력을 1차원 벡터로 변환
FC + Softmax 출력
- 예: 분류 대상이 10개일 경우 (ex: 숫자 0~9)
- 출력층 shape: (10,)
→ 각각의 값은 클래스별 확률
📊 전체 구조 흐름 + Shape 변화 예시
단계설명출력 크기 예시
| 입력 이미지 | RGB 이미지 | (28, 28, 3) |
| Conv1 (필터 32개) | 특징 추출 | (28, 28, 32) |
| MaxPooling1 | 다운샘플링 | (14, 14, 32) |
| Conv2 (필터 64개) | 더 깊은 특징 추출 | (14, 14, 64) |
| MaxPooling2 | 다운샘플링 | (7, 7, 64) |
| Flatten | FC 입력용으로 변환 | (3136,) |
| FC Layer | 은닉층 | (128,) |
| Output Layer | 분류 결과 | (10,) |
'인공지능' 카테고리의 다른 글
| RNN (Recurrent Neural Network) (0) | 2025.03.27 |
|---|---|
| AlexNet (0) | 2025.03.21 |
| 다중 분류 (Multi-class Classification) (0) | 2025.03.21 |
| 이진 분류(Binary Classification) 모델 정리 (0) | 2025.03.21 |
| 선형 회귀 (Linear Regression) (0) | 2025.03.21 |


