🔍 RNN/LSTM의 한계를 극복한 모델
기존의 순환 신경망(RNN, LSTM)은 데이터를 순차적으로 처리하면서 이전 정보를 다음 단계로 전달합니다. 그러나 이 구조에는 다음과 같은 한계가 존재합니다:
- 장기 의존성 문제 (Long-term Dependency)
입력 시퀀스가 길어질수록, 과거 정보가 사라지거나 잘 전달되지 않아 중요한 문맥을 놓칠 수 있습니다.
예: "나는 어릴 때부터 수학을 좋아했다. 그래서 나중에 수학자가 되기로 결심했다." → 이 문장에서 "어릴 때부터 수학을 좋아했다"는 정보가 마지막 문장에 중요하지만, RNN은 이를 잘 유지하지 못할 수 있습니다. - 병렬처리 불가능
시퀀스를 순차적으로 처리하기 때문에 학습과 추론 속도가 느림.
💡 Transformer의 등장
Transformer는 2017년 논문 "Attention is All You Need" 에서 처음 소개되었습니다. 이 모델은 다음과 같은 특징을 가집니다:
- Self-Attention 메커니즘 사용
- 순환 구조 없이 모든 입력을 동시에 처리 → 병렬 연산 가능
- 긴 시퀀스에서도 장기 의존성 문제 해결
🧠 대표적인 Transformer 기반 모델
모델특징
| BERT | 입력을 양방향으로 이해 (Bidirectional), 문장 의미 파악에 강함 |
| GPT | 한 방향(왼쪽→오른쪽)으로 학습, 문장 생성에 강함 |
| ViT | 이미지를 Transformer 구조로 처리, CNN 대체 가능 |
🔑 Transformer의 핵심 개념
📐 Positional Encoding (위치 인코딩)
Transformer는 문장 내 단어의 순서를 직접 인식하지 못합니다.
→ 따라서 단어의 위치 정보를 인코딩하여 입력에 추가합니다.
✔️ 적용 방법
- 입력 임베딩에 위치 벡터를 더함
- 위치 벡터는 sin, cos 함수 기반으로 생성 (예: 짝수 index는 sin, 홀수 index는 cos)
예를 들어, "나는 학교에 갔다" 라는 문장에서 "나는"과 "갔다"가 멀리 떨어져 있어도 Transformer는 위치 정보를 통해 문맥을 이해할 수 있습니다.
🔁 Self-Attention (자기-어텐션)
Self-Attention은 각 단어가 문장 내 다른 단어들을 얼마나 중요하게 여겨야 하는지를 계산하는 메커니즘입니다.
📌 주요 단계
- Query, Key, Value 생성
각 입력 벡터를 세 개의 행렬 (Q, K, V)로 변환
→ 의미상:- Query(Q): 내가 찾고 싶은 정보
- Key(K): 다른 단어들이 가진 정보의 키워드
- Value(V): 실제 정보
- 어텐션 스코어 계산
- Query와 Key 간의 내적(dot product)을 통해 유사도를 계산
- Softmax로 정규화하여 각 단어의 중요도 결정
- Weighted Sum 계산
- Value 벡터에 어텐션 가중치를 곱하여 최종 벡터 생성
- 이 벡터가 해당 단어의 문맥을 반영한 결과값이 됨
📋 수식 요약
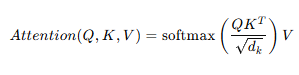
🌟 Transformer의 장점
장점설명
| 병렬 처리 가능 | 전체 시퀀스를 한 번에 처리하여 빠름 |
| 장기 의존성 처리 | Self-Attention으로 멀리 있는 단어도 연결 가능 |
| 높은 성능 | 기계 번역, 요약, 질의응답 등에서 SOTA 기록 달성 |
🖼️ Vision Transformer (ViT)
📷 Vision Transformer란?
Transformer를 이미지 처리에 적용한 모델로, 자연어 처리와 같은 구조를 이미지에도 사용합니다.
🔎 ViT의 특징
항목설명
| 패치 분할 | 이미지를 작은 패치(조각)로 나눈 후, 각각을 하나의 "단어"처럼 처리 |
| 입력 임베딩 | 각 패치를 선형 변환하여 입력 벡터로 만듬 |
| Positional Encoding 사용 | 패치의 순서를 표현하기 위해 위치 인코딩 추가 |
| Self-Attention 사용 | 각 패치가 다른 패치들과 어떻게 상호작용하는지 학습 |
| 학습 효율 | 적은 데이터로도 강력한 성능, 특히 사전 학습(pretraining) 후 fine-tuning 시 효과적 |
'인공지능' 카테고리의 다른 글
| GAN (Generative Adversarial Network) (0) | 2025.04.04 |
|---|---|
| MobileNet: 모바일을 위한 경량 CNN (0) | 2025.04.04 |
| GAN 전체 정리 (0) | 2025.03.31 |
| 전이 학습 (Transfer Learning) (0) | 2025.03.27 |
| CNN 아키텍처 발전 흐름 요약 (0) | 2025.03.27 |
